Chapter 21Project: Skill-Sharing Website
A skill-sharing meeting is an event where people with a shared interest come together and give small, informal presentations about things they know. At a gardening skill-sharing meeting, someone might explain how to cultivate celery. Or in a programming-oriented skill-sharing group, you could drop by and tell everybody about Node.js.
Such meetups, also often called users’ groups when they are about computers, are a great way to broaden your horizon, learn about new developments, or simply meet people with similar interests. Many large cities have a JavaScript meetup. They are typically free to attend, and I’ve found the ones I’ve visited to be friendly and welcoming.
In this final project chapter, our goal is to set up a website for managing talks given at a skill-sharing meeting. Imagine a small group of people meeting up regularly in a member’s office to talk about unicycling. The problem is that when the previous organizer of the meetings moved to another town, nobody stepped forward to take over this task. We want a system that will let the participants propose and discuss talks among themselves, without a central organizer.

Just like in the previous chapter, the code in this chapter is written for Node.js, and running it directly in the HTML page that you are looking at is unlikely to work. The full code for the project can be downloaded from eloquentjavascript.net/2nd_edition/code/skillsharing.zip.
Design
There is a server part to this project, written for Node.js, and a client part, written for the browser. The server stores the system’s data and provides it to the client. It also serves the HTML and JavaScript files that implement the client-side system.
The server keeps a list of talks proposed for the next meeting, and the client shows this list. Each talk has a presenter name, a title, a summary, and a list of comments associated with it. The client allows users to propose new talks (adding them to the list), delete talks, and comment on existing talks. Whenever the user makes such a change, the client makes an HTTP request to tell the server about it.
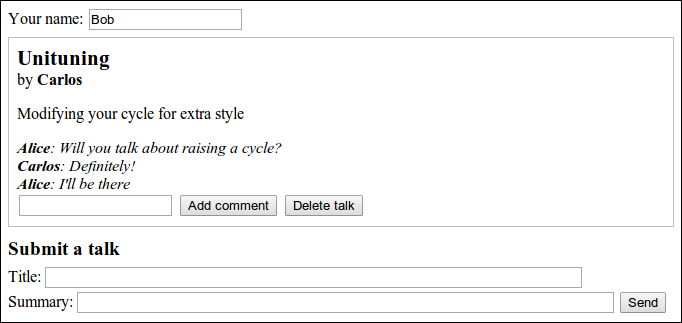
The application will be set up to show a live view of the current proposed talks and their comments. Whenever someone, somewhere, submits a new talk or adds a comment, all people who have the page open in their browsers should immediately see the change. This poses a bit of a challenge since there is no way for a web server to open up a connection to a client, nor is there a good way to know which clients currently are looking at a given website.
A common solution to this problem is called long polling, which happens to be one of the motivations for Node’s design.
Long polling
To be able to immediately notify a client that something changed, we need a connection to that client. Since web browsers do not traditionally accept connections and clients are usually behind devices that would block such connections anyway, having the server initiate this connection is not practical.
We can arrange for the client to open the connection and keep it around so that the server can use it to send information when it needs to do so.
But an HTTP request allows only a simple flow of information, where the client sends a request, the server comes back with a single response, and that is it. There is a technology called web sockets, supported by modern browsers, which makes it possible to open connections for arbitrary data exchange. But using them properly is somewhat tricky.
In this chapter, we will use a relatively simple technique, long polling, where clients continuously ask the server for new information using regular HTTP requests, and the server simply stalls its answer when it has nothing new to report.
As long as the client makes sure it constantly has a polling request open, it will receive information from the server immediately. For example, if Alice has our skill-sharing application open in her browser, that browser will have made a request for updates and be waiting for a response to that request. When Bob submits a talk on Extreme Downhill Unicycling, the server will notice that Alice is waiting for updates and send information about the new talk as a response to her pending request. Alice’s browser will receive the data and update the screen to show the talk.
To prevent connections from timing out (being aborted because of a lack of activity), long-polling techniques usually set a maximum time for each request, after which the server will respond anyway, even though it has nothing to report, and the client will start a new request. Periodically restarting the request also makes the technique more robust, allowing clients to recover from temporary connection failures or server problems.
A busy server that is using long polling may have thousands of waiting requests, and thus TCP connections, open. Node, which makes it easy to manage many connections without creating a separate thread of control for each one, is a good fit for such a system.
HTTP interface
Before we start fleshing out either the server or the client, let’s think about the point where they touch: the HTTP interface over which they communicate.
We will base our interface on JSON, and like in the file server
from Chapter 20, we’ll try to make good use
of HTTP methods. The interface is centered around the /talks path.
Paths that do not start with /talks will be used for
serving static files—the HTML and JavaScript code that implements
the client-side system.
A GET request to /talks returns a JSON document
like this:
{"serverTime": 1405438911833,
"talks": [{"title": "Unituning",
"presenter": "Carlos",
"summary": "Modifying your cycle for extra style",
"comment": []}]}
The serverTime field will be used to make reliable long polling
possible. I will return to it
later.
Creating a new talk is done by making a PUT
request to a URL like /talks/Unituning, where the part after the
second slash is the title of the talk. The PUT request’s body should
contain a JSON object that has presenter and summary
properties.
Since talk titles may contain spaces and other
characters that may not appear normally in a URL, title strings must be encoded
with the encodeURIComponent function when building up such a URL.
console.log("/talks/" + encodeURIComponent("How to Idle")); // → /talks/How%20to%20Idle
A request to create a talk about idling might look something like this:
PUT /talks/How%20to%20Idle HTTP/1.1 Content-Type: application/json Content-Length: 92 {"presenter": "Dana", "summary": "Standing still on a unicycle"}
Such URLs also support GET requests to retrieve the JSON
representation of a talk and DELETE requests to delete a talk.
Adding a comment to a talk is done with a POST
request to a URL like /talks/Unituning/comments, with a JSON object
that has author and message properties as the body of the request.
POST /talks/Unituning/comments HTTP/1.1 Content-Type: application/json Content-Length: 72 {"author": "Alice", "message": "Will you talk about raising a cycle?"}
To support long polling, GET
requests to /talks may include a query parameter called changesSince,
which is used to indicate that the client is interested in updates
that happened since a given point in time. When there are such
changes, they are immediately returned. When there aren’t, the response is
delayed until something happens or until a given time period (we will use
90 seconds) has elapsed.
The time
must be indicated as the number of milliseconds elapsed since the
start of 1970, the same type of number that is returned by
Date.now(). To ensure that it receives all updates and
doesn’t receive the same update more than once, the client must pass
the time at which it last received information from the server. The
server’s clock might not be exactly in sync with the client’s clock,
and even if it were, it would be impossible for the client to know the
precise time at which the server sent a response because
transferring data over the network takes time.
This is the reason for the existence of the serverTime property in
responses sent to GET requests to /talks. That property tells the client the
precise time, from the server’s perspective, at which the data it
receives was created. The client can then simply store this time and pass it
along in its next polling request to make sure that it receives
exactly the updates that it has not seen before.
GET /talks?changesSince=1405438911833 HTTP/1.1
(time passes)
HTTP/1.1 200 OK
Content-Type: application/json
Content-Length: 95
{"serverTime": 1405438913401,
"talks": [{"title": "Unituning",
"deleted": true}]}
When a talk has been changed, has been newly created, or has a comment added,
the full representation of the talk is included in the response to
the client’s next polling request. When a talk is deleted, only its title and the
property deleted are included. The client can then add talks with
titles it has not seen before to its display, update talks that it was
already showing, and remove those that were deleted.
The protocol described in this chapter does not do any access control. Everybody can comment, modify talks, and even delete them. Since the Internet is filled with hooligans, putting such a system online without further protection is likely to end in disaster.
A simple solution would be to put the system behind a reverse proxy, which is an HTTP server that accepts connections from outside the system and forwards them to HTTP servers that are running locally. Such a proxy can be configured to require a username and password, and you could make sure only the participants in the skill-sharing group have this password.
The server
Let’s start by writing the server-side part of the program. The code in this section runs on Node.js.
Routing
Our server will use
http.createServer to start an HTTP server. In the function that
handles a new request, we must distinguish between the various kinds
of requests (as determined by the method and the path) that we
support. This can be done with a long chain of if statements, but
there is a nicer way.
A router is a component that helps dispatch a
request to the function that can handle it. You can tell the router, for
example, that PUT requests with a path that
matches the regular expression /^\/talks\/([^\/]+)$/ (which matches /talks/
followed by a talk title) can be handled by a given function. In
addition, it can help extract the meaningful parts of the path, in this
case the talk title, wrapped in parentheses in the regular expression and pass those to the handler function.
There are a number of good router packages on NPM, but here we will write one ourselves to illustrate the principle.
This is
router.js, which we will later require from our server module:
var Router = module.exports = function() { this.routes = []; }; Router.prototype.add = function(method, url, handler) { this.routes.push({method: method, url: url, handler: handler}); }; Router.prototype.resolve = function(request, response) { var path = require("url").parse(request.url).pathname; return this.routes.some(function(route) { var match = route.url.exec(path); if (!match || route.method != request.method) return false; var urlParts = match.slice(1).map(decodeURIComponent); route.handler.apply(null, [request, response] .concat(urlParts)); return true; }); };
The module exports the Router constructor. A router
object allows new handlers to be registered with the add method and
can resolve requests with its resolve method.
The latter will return a Boolean that indicates
whether a handler was found. The some method on the
array of routes will try the routes one at a time (in the order in
which they were defined) and stop, returning true, when a matching
one is found.
The handler functions are called with the request and
response objects. When the regular expression that matches the
URL contains any groups, the strings they match are passed to the handler
as extra arguments. These strings have to be URL-decoded since the raw URL
contains %20-style codes.
Serving files
When a request matches none of the request types defined in our
router, the server must interpret it as a request for a file in
the public directory. It would be possible to use the file server
defined in Chapter 20 to serve such
files, but we neither need nor want to support PUT and
DELETE requests on files, and we would like to have advanced
features such as support for caching. So let’s use a solid, well-tested
static file server from NPM instead.
I opted for
ecstatic. This isn’t the only such server on NPM, but it works
well and fits our purposes. The ecstatic module exports a function
that can be called with a configuration object to produce a request
handler function. We use the root option to tell the server where it
should look for files. The handler function accepts request and
response parameters and can be passed directly to createServer to
create a server that serves only files. We want to first check for
requests that we handle specially, though, so we wrap it in another
function.
var http = require("http"); var Router = require("./router"); var ecstatic = require("ecstatic"); var fileServer = ecstatic({root: "./public"}); var router = new Router(); http.createServer(function(request, response) { if (!router.resolve(request, response)) fileServer(request, response); }).listen(8000);
The respond and respondJSON helper functions are used throughout the
server code to send off responses with a single function call.
function respond(response, status, data, type) { response.writeHead(status, { "Content-Type": type || "text/plain" }); response.end(data); } function respondJSON(response, status, data) { respond(response, status, JSON.stringify(data), "application/json"); }
Talks as resources
The server keeps the talks that have been proposed in an object
called talks, whose property names are the talk titles. These will
be exposed as HTTP resources under /talks/[title], so we need to
add handlers to our router that implement the various methods that
clients can use to work with them.
The handler for requests
that GET a single talk must look up the talk and respond either with
the talk’s JSON data or with a 404 error response.
var talks = Object.create(null); router.add("GET", /^\/talks\/([^\/]+)$/, function(request, response, title) { if (title in talks) respondJSON(response, 200, talks[title]); else respond(response, 404, "No talk '" + title + "' found"); });
Deleting a talk is done by removing it from the
talks object.
router.add("DELETE", /^\/talks\/([^\/]+)$/, function(request, response, title) { if (title in talks) { delete talks[title]; registerChange(title); } respond(response, 204, null); });
The registerChange function, which we
will define later, notifies
waiting long-polling requests about the change.
To retrieve
the content of JSON-encoded request bodies, we define a
function called readStreamAsJSON, which reads all content from a stream,
parses it as JSON, and then calls a callback function.
function readStreamAsJSON(stream, callback) { var data = ""; stream.on("data", function(chunk) { data += chunk; }); stream.on("end", function() { var result, error; try { result = JSON.parse(data); } catch (e) { error = e; } callback(error, result); }); stream.on("error", function(error) { callback(error); }); }
One handler that
needs to read JSON responses is the PUT handler, which is used to create new
talks. It has to check whether the data it was given has
presenter and summary properties, which are strings. Any data
coming from outside the system might be nonsense, and we don’t want to
corrupt our internal data model, or even crash, when bad requests
come in.
If the data looks valid, the handler
stores an object that represents the new talk in the talks object,
possibly overwriting an existing talk with this title, and again
calls registerChange.
router.add("PUT", /^\/talks\/([^\/]+)$/, function(request, response, title) { readStreamAsJSON(request, function(error, talk) { if (error) { respond(response, 400, error.toString()); } else if (!talk || typeof talk.presenter != "string" || typeof talk.summary != "string") { respond(response, 400, "Bad talk data"); } else { talks[title] = {title: title, presenter: talk.presenter, summary: talk.summary, comments: []}; registerChange(title); respond(response, 204, null); } }); });
Adding a comment to
a talk works similarly. We use readStreamAsJSON to
get the content of the request, validate the resulting data, and store
it as a comment when it looks valid.
router.add("POST", /^\/talks\/([^\/]+)\/comments$/, function(request, response, title) { readStreamAsJSON(request, function(error, comment) { if (error) { respond(response, 400, error.toString()); } else if (!comment || typeof comment.author != "string" || typeof comment.message != "string") { respond(response, 400, "Bad comment data"); } else if (title in talks) { talks[title].comments.push(comment); registerChange(title); respond(response, 204, null); } else { respond(response, 404, "No talk '" + title + "' found"); } }); });
Trying to add a comment to a nonexistent talk should return a 404 error, of course.
Long-polling support
The most interesting aspect of the server is the part that handles
long polling. When a GET request comes in for /talks, it can
be either a simple request for all talks or a request for
updates, with a changesSince parameter.
There will be various situations in which we have to send a list of
talks to the client, so we first define a small helper function that
attaches the serverTime field to such responses.
function sendTalks(talks, response) { respondJSON(response, 200, { serverTime: Date.now(), talks: talks }); }
The handler itself
needs to look at the query parameters in the request’s URL to see
whether a changesSince parameter is given. If you give the "url" module’s
parse function a second argument of true, it will
also parse the query part of a URL. The object it returns will have a
query property, which holds another object that maps parameter names to
values.
router.add("GET", /^\/talks$/, function(request, response) { var query = require("url").parse(request.url, true).query; if (query.changesSince == null) { var list = []; for (var title in talks) list.push(talks[title]); sendTalks(list, response); } else { var since = Number(query.changesSince); if (isNaN(since)) { respond(response, 400, "Invalid parameter"); } else { var changed = getChangedTalks(since); if (changed.length > 0) sendTalks(changed, response); else waitForChanges(since, response); } } });
When the changesSince parameter is missing, the handler simply
builds up a list of all talks and returns that.
Otherwise, the changesSince
parameter first has to be checked to make sure that it is a valid
number. The getChangedTalks function, to be defined shortly, returns
an array of changed talks since a given point in time. If it returns an
empty array, the server does not yet have anything to send back to the
client, so it stores the response object (using waitForChanges) to
be responded to at a later time.
var waiting = []; function waitForChanges(since, response) { var waiter = {since: since, response: response}; waiting.push(waiter); setTimeout(function() { var found = waiting.indexOf(waiter); if (found > -1) { waiting.splice(found, 1); sendTalks([], response); } }, 90 * 1000); }
The splice method is used to cut a piece out of an array.
You give it an index and a number of elements, and it mutates the
array, removing that many elements after the given index. In this
case, we remove a single element, the object that tracks the waiting
response, whose index we found by calling indexOf. If you pass
additional arguments to splice, their values will be inserted into
the array at the given position, replacing the removed elements.
When a response object is stored
in the waiting array, a timeout is immediately set. After 90
seconds, this timeout sees whether the request is still waiting and, if it
is, sends an empty response and removes it from the waiting array.
To be able to find exactly those talks
that have been changed since a given point in time, we need to keep
track of the history of changes. Registering a change with
registerChange will remember that change, along with the current
time, in an array called changes. When a change occurs, that means
there is new data, so all waiting requests can be responded to
immediately.
var changes = []; function registerChange(title) { changes.push({title: title, time: Date.now()}); waiting.forEach(function(waiter) { sendTalks(getChangedTalks(waiter.since), waiter.response); }); waiting = []; }
Finally, getChangedTalks uses the changes array to build up an
array of changed talks, including objects with a deleted property for
talks that no longer exist. When building that array, getChangedTalks has to ensure that it
doesn’t include the same talk twice since there might have been
multiple changes to a talk since the given time.
function getChangedTalks(since) { var found = []; function alreadySeen(title) { return found.some(function(f) {return f.title == title;}); } for (var i = changes.length - 1; i >= 0; i--) { var change = changes[i]; if (change.time <= since) break; else if (alreadySeen(change.title)) continue; else if (change.title in talks) found.push(talks[change.title]); else found.push({title: change.title, deleted: true}); } return found; }
That concludes the server code. Running the program defined so far
will get you a server running on port 8000, which serves files from
the public subdirectory alongside a talk-managing interface under
the /talks URL.
The client
The client-side part of the talk-managing website consists of three files: an HTML page, a style sheet, and a JavaScript file.
HTML
It is a widely used convention for web servers to try
to serve a file named index.html when a request is made directly
to a path that corresponds to a directory. The file server module
we use, ecstatic, supports this convention. When a request is made
to the path /, the server looks for the file ./public/index.html (./public
being the root we gave it) and returns that file if found.
Thus, if we want a page to show up when a browser is pointed at our
server, we should put it in public/index.html. This is how our index
file starts:
<title>Skill Sharing</title> <link rel="stylesheet" href="skillsharing.css"> <h1>Skill sharing</h1> <p>Your name: <input type="text" id="name"></p> <div id="talks"></div>
It defines the document title and includes a style sheet, which defines a few styles to, among other things, add a border around talks. Then it adds a heading and a name field. The user is expected to put their name in the latter so that it can be attached to talks and comments they submit.
The <div> element with the ID
"talks" will contain the current list of talks. The script fills the list
in when it receives talks from the server.
Next comes the form that is used to create a new talk.
<form id="newtalk"> <h3>Submit a talk</h3> Title: <input type="text" style="width: 40em" name="title"> <br> Summary: <input type="text" style="width: 40em" name="summary"> <button type="submit">Send</button> </form>
The script will add a "submit" event handler to
this form, from which it can make the HTTP request that tells the
server about the talk.
Next comes a rather mysterious
block, which has its display style set to none, preventing it from
actually showing up on the page. Can you guess what it is for?
<div id="template" style="display: none"> <div class="talk"> <h2>{{title}}</h2> <div>by <span class="name">{{presenter}}</span></div> <p>{{summary}}</p> <div class="comments"></div> <form> <input type="text" name="comment"> <button type="submit">Add comment</button> <button type="button" class="del">Delete talk</button> </form> </div> <div class="comment"> <span class="name">{{author}}</span>: {{message}} </div> </div>
Creating complicated DOM structures with
JavaScript code produces ugly code. You can make the code slightly better by
introducing helper functions like the elt function from
Chapter 13, but the result will still look worse
than HTML, which can be thought of as a domain-specific language
for expressing DOM structures.
To create DOM structures for the talks, our program will define a simple templating system, which uses hidden DOM structures included in the document to instantiate new DOM structures, replacing the placeholders between double braces with the values of a specific talk.
Finally, the HTML document includes the script file that contains the client-side code.
<script src="skillsharing_client.js"></script>
Starting up
The first thing the client has
to do when the page is loaded is ask the server for the current set
of talks. Since we are going to make a lot of HTTP requests, we will
again define a small wrapper around XMLHttpRequest, which accepts an
object to configure the request as well as a callback to call when the
request finishes.
function request(options, callback) { var req = new XMLHttpRequest(); req.open(options.method || "GET", options.pathname, true); req.addEventListener("load", function() { if (req.status < 400) callback(null, req.responseText); else callback(new Error("Request failed: " + req.statusText)); }); req.addEventListener("error", function() { callback(new Error("Network error")); }); req.send(options.body || null); }
The initial request displays the talks it
receives on the screen and starts the long-polling process by calling
waitForChanges.
var lastServerTime = 0; request({pathname: "talks"}, function(error, response) { if (error) { reportError(error); } else { response = JSON.parse(response); displayTalks(response.talks); lastServerTime = response.serverTime; waitForChanges(); } });
The lastServerTime variable is used to track
the time of the last update that was received from the server.
After the initial request, the client’s view of the talks corresponds
to the view that the server had when it responded to that request.
Thus, the serverTime property included in the response provides an
appropriate initial value for lastServerTime.
When the request fails, we
don’t want to have our page just sit there, doing nothing without
explanation. So we define a simple function called reportError, which at
least shows the user a dialog that tells them something went wrong.
function reportError(error) { if (error) alert(error.toString()); }
The function checks whether there is an
actual error, and it alerts only when there is one. That way, we can also
directly pass this function to request for requests where we can ignore the
response. This makes sure that if the request fails, the error is reported
to the user.
Displaying talks
To be able to update the view of the talks when changes come in, the client must keep track of the talks that it is currently showing. That way, when a new version of a talk that is already on the screen comes in, the talk can be replaced (in place) with its updated form. Similarly, when information comes in that a talk is being deleted, the right DOM element can be removed from the document.
The function displayTalks is used both to build up the initial
display and to update it when something changes. It will use the
shownTalks object, which associates talk titles with DOM nodes, to
remember the talks it currently has on the screen.
var talkDiv = document.querySelector("#talks"); var shownTalks = Object.create(null); function displayTalks(talks) { talks.forEach(function(talk) { var shown = shownTalks[talk.title]; if (talk.deleted) { if (shown) { talkDiv.removeChild(shown); delete shownTalks[talk.title]; } } else { var node = drawTalk(talk); if (shown) talkDiv.replaceChild(node, shown); else talkDiv.appendChild(node); shownTalks[talk.title] = node; } }); }
Building up the DOM
structure for talks is done using the templates that were included
in the HTML document. First, we must define instantiateTemplate,
which looks up and fills in a template.
The name parameter is the
template’s name. To look up the template element, we search for an
element whose class name matches the template name, which is a child
of the element with ID "template". Using the querySelector method
makes this easy. There were templates named "talk" and "comment" in
the HTML page.
function instantiateTemplate(name, values) { function instantiateText(text) { return text.replace(/\{\{(\w+)\}\}/g, function(_, name) { return values[name]; }); } function instantiate(node) { if (node.nodeType == document.ELEMENT_NODE) { var copy = node.cloneNode(); for (var i = 0; i < node.childNodes.length; i++) copy.appendChild(instantiate(node.childNodes[i])); return copy; } else if (node.nodeType == document.TEXT_NODE) { return document.createTextNode( instantiateText(node.nodeValue)); } else { return node; } } var template = document.querySelector("#template ." + name); return instantiate(template); }
The
cloneNode method, which all DOM nodes have, creates a copy of a
node. It won’t copy the node’s child nodes unless true is given as
a first argument. The instantiate function recursively builds up a
copy of the template, filling in the template as it goes.
The second argument to instantiateTemplate should be an object,
whose properties hold the strings that are to be filled into the
template. A placeholder like {{title}} will be replaced with the
value of values’ title property.
This is a crude approach to templating, but it
is enough to implement drawTalk.
function drawTalk(talk) { var node = instantiateTemplate("talk", talk); var comments = node.querySelector(".comments"); talk.comments.forEach(function(comment) { comments.appendChild( instantiateTemplate("comment", comment)); }); node.querySelector("button.del").addEventListener( "click", deleteTalk.bind(null, talk.title)); var form = node.querySelector("form"); form.addEventListener("submit", function(event) { event.preventDefault(); addComment(talk.title, form.elements.comment.value); form.reset(); }); return node; }
After instantiating the "talk" template, there
are various things that need to be patched up. First, the comments
have to be filled in by repeatedly instantiating the "comment"
template and appending the results to the node with class
"comments". Next, event handlers have to be attached to the button
that deletes the task and the form that adds a new comment.
Updating the server
The event handlers registered by drawTalk call the function
deleteTalk and addComment to perform the actual actions required
to delete a talk or add a comment. These will need to build up
URLs that refer to talks with a given title, for which we define
the talkURL helper function.
function talkURL(title) { return "talks/" + encodeURIComponent(title); }
The deleteTalk function fires off a DELETE
request and reports the error when that fails.
function deleteTalk(title) { request({pathname: talkURL(title), method: "DELETE"}, reportError); }
Adding a comment requires building up a JSON
representation of the comment and submitting that as part of a POST
request.
function addComment(title, comment) { var comment = {author: nameField.value, message: comment}; request({pathname: talkURL(title) + "/comments", body: JSON.stringify(comment), method: "POST"}, reportError); }
The nameField variable used to
set the comment’s author property is a reference to the <input>
field at the top of the page that allows the user to specify their
name. We also wire up that field to localStorage so that it does
not have to be filled in again every time the page is reloaded.
var nameField = document.querySelector("#name"); nameField.value = localStorage.getItem("name") || ""; nameField.addEventListener("change", function() { localStorage.setItem("name", nameField.value); });
The form at the
bottom of the page, for proposing a new talk, gets a "submit" event
handler. This handler prevents the event’s default effect (which would
cause a page reload), clears the form, and fires off a PUT request
to create the talk.
var talkForm = document.querySelector("#newtalk"); talkForm.addEventListener("submit", function(event) { event.preventDefault(); request({pathname: talkURL(talkForm.elements.title.value), method: "PUT", body: JSON.stringify({ presenter: nameField.value, summary: talkForm.elements.summary.value })}, reportError); talkForm.reset(); });
Noticing changes
I should point out that the various functions that change the state of the application by creating or deleting talks or adding a comment do absolutely nothing to ensure that the changes they make are visible on the screen. They simply tell the server and rely on the long-polling mechanism to trigger the appropriate updates to the page.
Given the mechanism that we implemented in our server and the way we
defined displayTalks to handle updates of talks that are already on
the page, the actual long polling is surprisingly simple.
function waitForChanges() { request({pathname: "talks?changesSince=" + lastServerTime}, function(error, response) { if (error) { setTimeout(waitForChanges, 2500); console.error(error.stack); } else { response = JSON.parse(response); displayTalks(response.talks); lastServerTime = response.serverTime; waitForChanges(); } }); }
This function is
called once when the program starts up and then keeps calling itself
to ensure that a polling request is always active. When the request
fails, we don’t call reportError since popping up a dialog every
time we fail to reach the server would get annoying when the
server is down. Instead, the error is written to the console (to ease
debugging), and another attempt is made 2.5 seconds later.
When the request succeeds, the new data is put onto the screen, and
lastServerTime is updated to reflect the fact that we received data
corresponding to this new point in time. The request is immediately
restarted to wait for the next update.
If you run the server and open two browser windows for localhost:8000/ next to each other, you can see that the actions you perform in one window are immediately visible in the other.
Exercises
The following exercises will involve modifying the system defined in this chapter. To work on them, make sure you download the code first (eloquentjavascript.net/2nd_edition/code/skillsharing.zip) and have Node installed (nodejs.org).
Disk persistence
The skill-sharing server keeps its data purely in memory. This means that when it crashes or is restarted for any reason, all talks and comments are lost.
Extend the server so that it stores the talk data to disk and automatically reloads the data when it is restarted. Do not worry about efficiency—do the simplest thing that works.
The simplest solution I can come up with
is to encode the whole talks object as JSON and dump it
to a file with fs.writeFile. There is already a function
(registerChange) that is called every time the server’s data
changes. It can be extended to write the new data to disk.
Pick a filename, for example
./talks.json. When the server starts, it can try to read that
file with fs.readFile, and if that succeeds, the server can use the
file’s contents as its starting data.
Beware, though. The talks
object started as a prototype-less object so that the in
operator could be sanely used. JSON.parse will return regular
objects with Object.prototype as their prototype. If you use JSON as
your file format, you’ll have to copy the properties of the object
returned by JSON.parse into a new, prototype-less object.
Comment field resets
The wholesale redrawing of talks works pretty well because you usually can’t tell the difference between a DOM node and its identical replacement. But there are exceptions. If you start typing something in the comment field for a talk in one browser window and then, in another, add a comment to that talk, the field in the first window will be redrawn, removing both its content and its focus.
In a heated discussion, where multiple people are adding comments to a single talk, this would be very annoying. Can you come up with a way to avoid it?
The ad hoc approach is to simply store the state of a talk’s comment field (its content and whether it is focused) before redrawing the talk and then reset the field to its old state afterward.
Another solution would be to not simply replace the old DOM structure with the new one but recursively compare them, node by node, and update only the parts that actually changed. This is a lot harder to implement, but it’s more general and continues working even if we add another text field.
Better templates
Most
templating systems do more than just fill in some strings. At the very
least, they also allow conditional inclusion of parts of the template,
analogous to if statements, and repetition of parts of a template,
similar to a loop.
If we were able to repeat a piece of template for each element in an
array, we would not need the second template ("comment"). Rather, we
could specify the "talk" template to loop over the array held in
a talk’s comments property and render the nodes that make up a
comment for every element in the array.
<div class="comments"> <div class="comment" template-repeat="comments"> <span class="name">{{author}}</span>: {{message}} </div> </div>
The idea is that whenever a node
with a template-repeat attribute is found during template
instantiation, the instantiating code loops over the array held in the
property named by that attribute. For each element in the array, it
adds an instance of the node. The template’s context (the values
variable in instantiateTemplate) would, during this loop, point at
the current element of the array so that {{author}} would be looked up
in the comment object rather than in the original context (the talk).
Rewrite
instantiateTemplate to implement this and then change the templates
to use this feature and remove the explicit rendering of comments from
the drawTalk function.
How would you add conditional instantiation of nodes, making it possible to omit parts of the template when a given value is true or false?
You
could change instantiateTemplate so that its inner function
takes not just a node but also a current context as an argument. You can
then, when looping over a node’s child nodes, check whether the child
has a template-repeat attribute. If it does, don’t instantiate it
once but instead loop over the array indicated by the attribute’s
value and instantiate it once for every element in the array, passing
the current array element as context.
Conditionals can be implemented in a similar way, with attributes
called, for example, template-when and template-unless, which
cause a node to be instantiated only when a given property is true (or
false).
The unscriptables
When someone visits our website with a browser that has JavaScript disabled or is simply not capable of displaying JavaScript, they will get a completely broken, inoperable page. This is not nice.
Some types of web applications really can’t be done without JavaScript. For others, you just don’t have the budget or patience to bother about clients that can’t run scripts. But for pages with a wide audience, it is polite to support scriptless users.
Try to think of a way the skill-sharing website could be set up to preserve basic functionality when run without JavaScript. The automatic updates will have to go, and people will have to refresh their page the old-fashioned way. But being able to see existing talks, create new ones, and submit comments would be nice.
Don’t feel obliged to actually implement this. Outlining a solution is enough. Does the revised approach strike you as more or less elegant than what we did initially?
Two central aspects of the
approach taken in this chapter—a clean HTTP interface and client-side
template rendering—don’t work without JavaScript. Normal HTML forms
can send GET and POST requests but not PUT or DELETE requests
and can send their data only to a fixed URL.
Thus, the server
would have to be revised to accept comments, new talks, and deleted
talks through POST requests, whose bodies aren’t JSON but rather
use the URL-encoded format that HTML forms use (see
Chapter 17). These requests would have to
return the full new page so that users see the new state of the site
after they make a change. This would not be too hard to engineer and
could be implemented alongside the “clean” HTTP interface.
The code for rendering talks would have to be duplicated
on the server. The index.html file, rather than being a static file,
would have to be generated dynamically by adding a handler for it to
the router. That way, it already includes the current talks and
comments when it gets served.